April 22, 2022
This article is part 1/13 (?) of a series of articles named Deep Learning with Python.
In this series, I will read through the second edition of Deep Learning with Python by François Chollet. Articles in this series will sequentially review key concepts, examples, and interesting facts from each chapter of the book.
Table of Contents
There are a few reasons why I picked this book over others:
About the author section below)Directly from the book...
François Chollet is the creator of Keras, one of the most widely used deep learning frameworks. He is currently [as of April 2022] a software engineer at Google, where he leads the Keras team. In addition, he does research on abstraction, reasoning, and how to achieve greater generality in artificial intelligence.
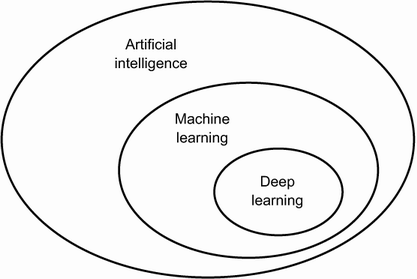
This chapter provides essential context around artificial intelligence (AI), machine learning (ML), and deep learning (DL).
AI can be described as the effort to automate intellectual tasks normally performed by humans. Artificial intelligence is a general field that encompasses machine learning and deep learning.
Early AI programs from the 1950s - such as Chess AI - involved hardcoded rules crafted by programmers. This approach is known as symbolic AIand was the dominant paradigm in AI from the 50s to the late 1980s. Symbolic AI reached its peak popularity during the expert systems boom of the 80s.
Symbolic AI is successful when applied to well-defined, logical problems like Chess or Go. However, symbolic AI fails when solving more complex, fuzzy problems because it's not possible to hardcode rules for such tasks. Perceptual tasks normally performed by humans - such as image classification, speech recognition, or natural language processing - are especially complex and cannot be accurately distilled into a set of rules.
By the early 1990s, expert systems were proven expensive to maintain, difficult to scale, and limited in scope. Interest in AI dwindled until the late 2000s when new machine learning approaches were developed.
Could a general-purpose computer "originate" anything, or would it always be bound to dully execute processes we humans fully understand? Could it learn from experience? Could it show creativity?
- Ada Lovelace's remarks on the invention of the Analytical Engine, 1843
Lovelace's remark was later quoted by AI pioneer Alan Turing as "Lady Lovelace's objection" in his landmark paper "Computing Machinery and Intelligence". Alan Turing's paper introduced the Turing test as well as key concepts that would come to shape AI.
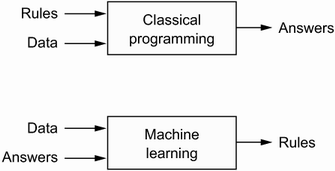
Classical programming is the usual way to make a computer perform useful tasks. A human programmer designs explicit rules - a computer program - to be followed. The computer, given a set of rules and input data, outputs appropriate answers.
Machine Learning flips this concept around: the computer looks at the input data and the appropriate answers, and figures out what the rules should be. ML systems are trained rather than explicitly programmed. Presented with many examples of a task (training data), the machine finds statistical structures in the examples and eventually allows the system to determine rules for automating the task.
Learning, in the context of ML, describes an automatic search process for data transformations that produces useful representations of data. The search process is guided by some feedback signal.
A machine learning model transforms its input data into meaningful outputs, a process that is "learned" from exposure to examples of inputs and outputs during training. Therefore, the central problem in ML is to meaningfully transform data. The transformations and representations are amenable to simpler rules for solving the task at hand.
In other words, ML's purpose is to learn useful representations of the input data at hand - representations that get us closer to the expected output.
In short, machine learning is searching for useful representations and rules over some input data, within a predefined space of possibilities, by performing data transformations and using guidance from a feedback signal. This simple idea allows for solving a remarkably broad range of intellectual tasks, from speech recognition to autonomous driving.
If that's not simple enough: Machine learning is about mapping inputs to labels - such as images of a cat to the label "cat" - by observing many examples of inputs and targets.
Deep learning is a specific subfield of machine learning. It's a new take on learning representations from data that emphasizes learning successive layers of increasingly meaningful representations. The "deep" in "deep learning" refers to successive layers of representations. How many layers contributes to a model of the data is called the depth of the model.
Most approaches to machine learning focus on learning only one or two layers of representations of the data; hence they're sometimes called shallow learning. Modern deep learning, on the other hand, often involves tens or even hundreds of successive layers of representations.
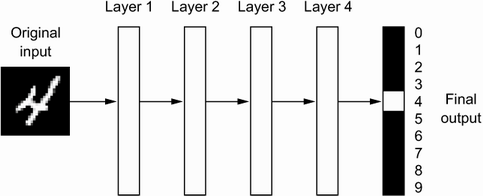
In DL, representations are learned via models called neural networks, structured in literal layers stacked on top of each other. Although the term "neural network" refers to neurobiology, and some central concepts in DL were developed in part by inspiration from our understanding of the brain, deep learning models are not models of the brain.
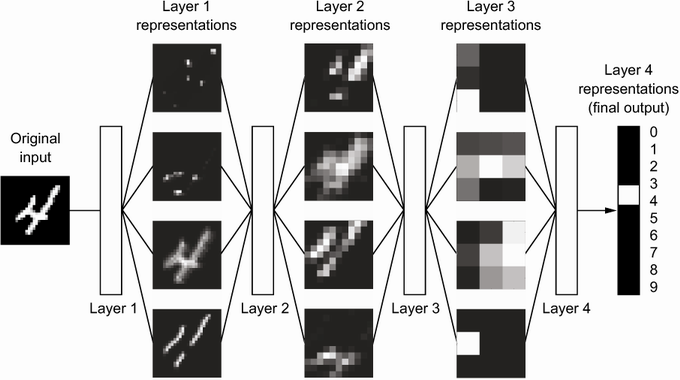
Given an input, such as an image, the neural network applies a sequence of simple data transformations to the image at each successive layer, creating a different data representation at each layer. As the image travels through the layers, representations become increasingly different from the original image and increasingly informative about the final result.
You can think of a deep network as a multistage information distillation process, where information goes through successive filters and come out increasingly purified.
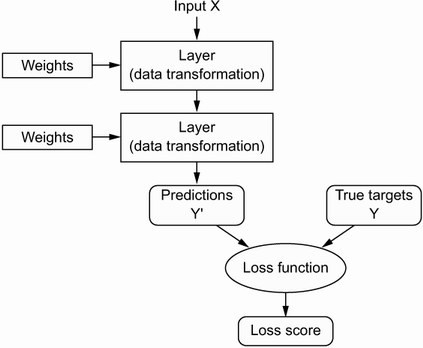
Recall that each layer performs a simple data transformation to the input to create a more pure, or simple, data representation. The specification of what a layer does to its input data - how the input is transformed - is stored in the layer's weights, which in essence are a bunch of numbers.
Technically, we'd say that the transformation implemented by a layer is parametrized by its weights. Weights are sometimes called the parameters of a layer.

In this context of DL and neural networks, learning means finding a set of values for the weights of all layers in a network, such that the network will correctly map example inputs to their associated targets. The correct set of weights is found by measuring how far the output is from what was expected, and adjusting the weights such that the output is incrementally closer to the expected output.
The output measurement and weight adjustment are the jobs of the network's loss function and optimizer, respectively.
The network's loss function - also sometimes called the objective or cost function - compares the network's prediction against the true target (what you wanted/expected the network to output), and computes a loss score. This loss score captures how well the network is doing during training.
The fundamental trick in deep learning is to use this score as a feedback signal for slightly adjusting the value of the layers' weights. The weight adjustment should move in a direction that will lower, or minimize, the loss score for the current example.
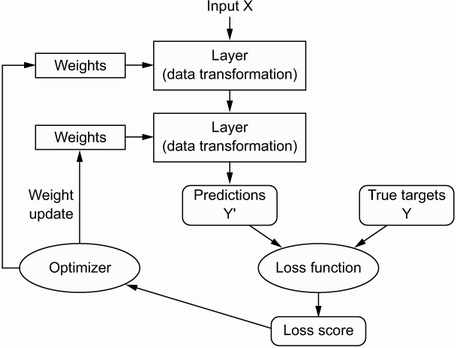
The weight adjustment is the job of the network's optimizer, which implements what's called the backpropagation algorithm: the central algorithm in DL. The next chapter explains in more detail how backpropagation works.
Initially, the weights of the network are assigned random values, so the network implements a series of random transformations. Naturally, the network's output is far from what it should ideally be, and the loss score is accordingly very high. With every example the network processes, the weights are slightly adjusted in the correct direction, and the loss score decreases.
This is the training loop, which, repeated a sufficient number of times (typically tens of iterations over thousands of examples), yields weight values that minimize the loss function.
A network with minimal loss is one for which the outputs are as close as they can be to the targets: a trained network.
Technically, deep learning is a multistage way to learn data representations. It's a simple idea with simple mechanisms that - when sufficiently scaled - end up looking like magic.
Deep learning rose to prominence in the early 2010s, following the boom of publicly-available data on the internet (images, videos from widespread use of cell phones and cameras) and faster processors. It has achieved nothing short of a revolution in the field of machine learning, producing remarkable results on perceptual tasks and even natural language processing tasks - problems involving skills that seem natural and intuitive to humans but have long been elusive for machines.
More specifically, deep learning has enabled the following breakthroughs, all in historically difficult areas of machine learning:
Deep learning is still a relatively new field of machine learning, but it has achieved a lot of progress in the last few years. It has delivered revolutions in the field of natural language processing, computer vision, and speech recognition.
There are three things needed to make deep learning work: input data, expected output data, and a measure of success. Deep learning models learn by predicting the output of some input data, and updating its knowledge based on the correctness of its prediction. The ultimate goal of deep learning is to create a model that transforms input data into useful representations in order to find the correct output for our problems.
We'll dive deeper into the details of DL in the following articles.